Count Elements
Count individual elements within text, such as words, characters or tokens. This can be particularly helpful for tasks such as checking the length of an article or essay, analyzing the readability of a document, or simply getting a quick overview of the amount of text that needs to be translated, edited or summarized.
Parameters
- Source Column: The column name containing the text you want to count by Count Type. This field is required, and it defaults to content.
- Destination Column: Enter the new name for the column that will hold the count result. This is a required field, and it defaults to count.
- Count Type: Select what you would like to count by (e.g., words, characters, sentences, etc.). This is a required field, and it defaults to words.
- LLM: The large language model used for counting tokens. LLM is only required when Count Type is token. Defaults to no-selection.
Usage
To use the Count Elements transformation in Mantium, follow these steps:
- Configure the Source Column parameter by selecting the column containing the text you want to analyze.
- Configure the Destination Column parameter by specifying the new name for the column that will hold the element count result.
- Configure the Count Type parameter by selecting the type of element you want to count.
- Optionally, configure the LLM parameter by selecting the tokenizer model to use for token counting.
- Run the transformation by clicking the Save and Run Transforms button. The resulting dataset will have a new column with the specified name containing the element count for each data point in the source column.
Example 1 - Word Count
Suppose you have a dataset containing article titles and you want to count the number of words in each title.
The video below demonstrates the example in just a few seconds. If you prefer text, please continue reading.
Sample Dataset:
| Article ID | Title |
|---|---|
| 1 | The Future of Artificial Intelligence |
| 2 | Climate Change and Its Impact on Ecosystems |
Configuration:
Source Column: Title
Destination Column: Word Count
Element Type: words
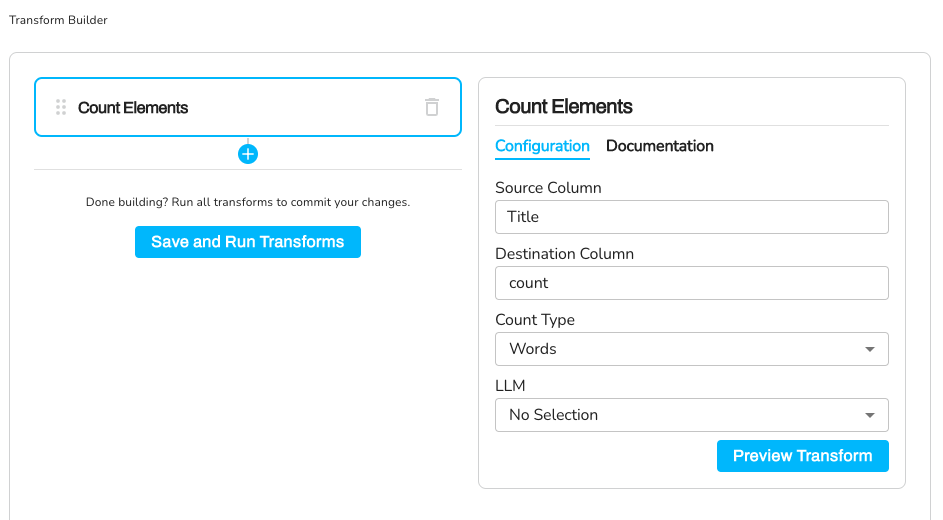
Transformation - Word Count
Expected Result Dataset:
| Article ID | Title | Word Count |
|---|---|---|
| 1 | The Future of Artificial Intelligence | 5 |
| 2 | Climate Change and Its Impact on Ecosystems | 7 |
Example 2 - Character Count
Suppose you have a dataset containing customer feedback, and you want to count the number of characters in each feedback entry.
The video below demonstrates the example in just a few seconds. If you prefer text, please continue reading.
Sample Dataset:
| Feedback ID | Feedback |
|---|---|
| 1 | Great product, fast shipping. |
| 2 | Had some issues, but customer support was helpful. |
Configuration:
Source Column: Feedback
Destination Column: Character Count
Element Type: characters
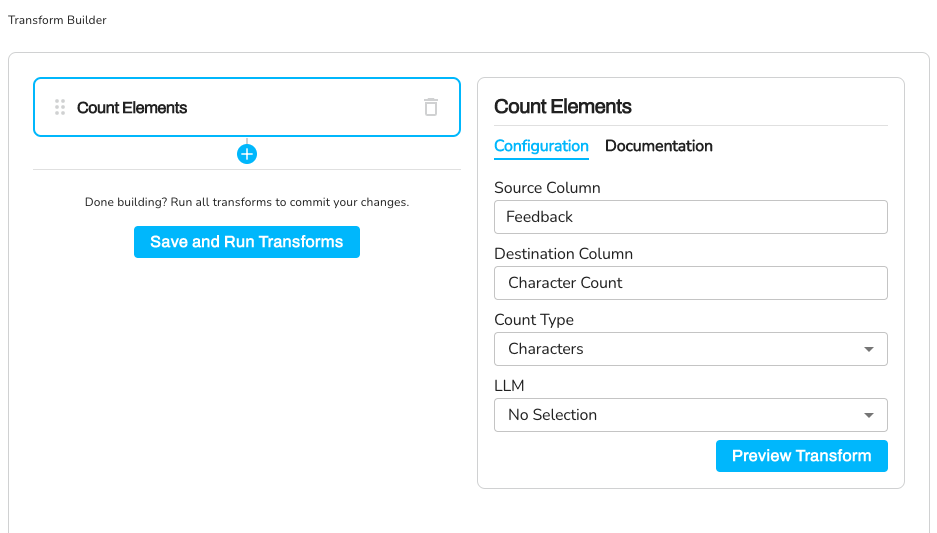
Transformation - Character Count
Expected Result Dataset:
| Feedback ID | Feedback | Character Count |
|---|---|---|
| 1 | Great product, fast shipping. | 29 |
| 2 | Had some issues, but customer support was helpful. | 50 |
Example 3 - Token Count
Suppose you have a dataset containing customer feedback in different languages, and you want to count the number of tokens in each feedback entry using the cl100k_base tokenizer.
The video below demonstrates the example in just a few seconds. If you prefer text, please continue reading.
Sample Dataset:
| Feedback ID | Feedback |
|---|---|
| 1 | Great product, fast shipping. |
| 2 | Très bon produit, livraison rapide. |
Configuration:
Source Column: Feedback
Destination Column: Token Count
Element Type: words
Tokenizer: cl100k_base
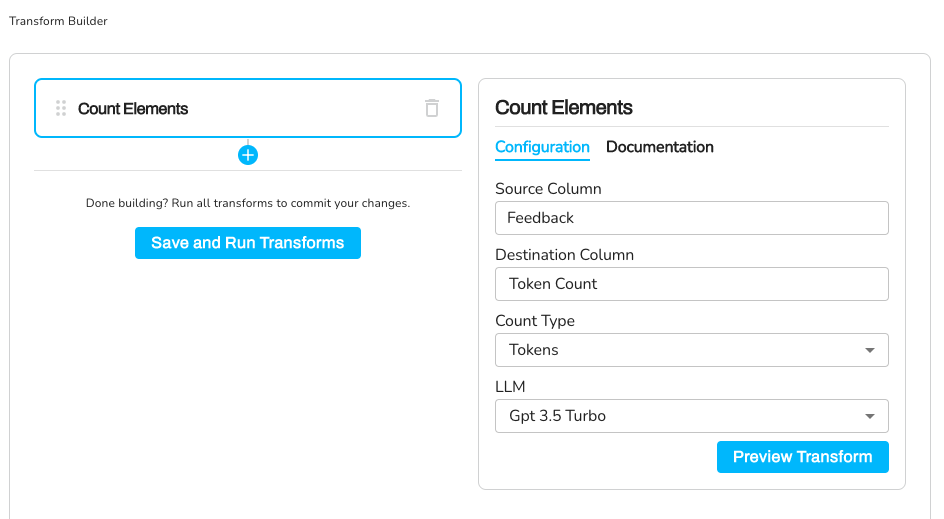
Transformation - Token Count
Expected Result Dataset:
| Feedback ID | Feedback | Token Count |
|---|---|---|
| 1 | Great product, fast shipping. | 6 |
| 2 | Très bon produit, livraison rapide. | 9 |
In this example, we use the cl100k_base tokenizer, which is more advanced and better suited for handling different languages and more complex tokenization tasks. The tokenizer recognizes punctuation as separate tokens and provides a more accurate count of tokens in the text.
Updated about 3 years ago