Generate Embeddings
Generate numerical representations of text, also known as embeddings, that can be used for tasks such as text classification, similarity analysis, and clustering. Embeddings capture the meaning and context of text in a way that can be processed by machine learning algorithms. They are commonly used in vector databases to enable efficient similarity search and retrieval of similar items.
Parameters
- Source Column: The column name containing the text you want to embed. Defaults to
content. - Destination Column: The column name that holds the embeddings. Defaults to
embeddings. - LLM: The large language model used to generate embeddings. Defaults to
text-embedding-ada-002. - Max Token Length: Maximum number of tokens that can be embedded by the LLM. If a cell exceeds the LLM’s maximum number of tokens, the text is truncated to fit the LLM’s maximum input limit. Defaults to
8191. - Credential ID: The OpenAI connector from your Mantium account.
Usage
To use the Generate Embeddings transformation, you will need to have a valid API key configured in Mantium for the third-party service (e.g., OpenAI) you want to use. If you don't have one, see the guide here
To use this Mantium Enrichment, follow these steps:
- Configure the Source Column parameter by selecting the column containing the text data you want to generate embeddings for.
- Configure the Destination Column parameter by specifying the new name for the column that will hold the embeddings.
- Configure the Embedding Model parameter by selecting the LLM model to use for the embedding.
- Optionally, configure the Max Token Length parameter by specifying the maximum length of the text input.
- Configure the Credential ID parameter by selecting the appropriate credential from the list of available credentials in your Mantium account.
- Run the transformation by clicking the Save and Run Transforms button. The resulting dataset will have a new column with the specified name containing the embeddings for the text data in the source column.
Example 1: Generating Text Embeddings for Product Reviews
Suppose you have a dataset of product reviews and you want to generate embeddings for the text in the "review" column. You can use the Generate Embeddings transformation to convert the text data into numerical embeddings.
Sample Dataset:
| Review ID | Review |
|---|---|
| 1 | Excellent product, really happy with my purchase. |
| 2 | Good quality but shipping took longer than expected. |
Config:
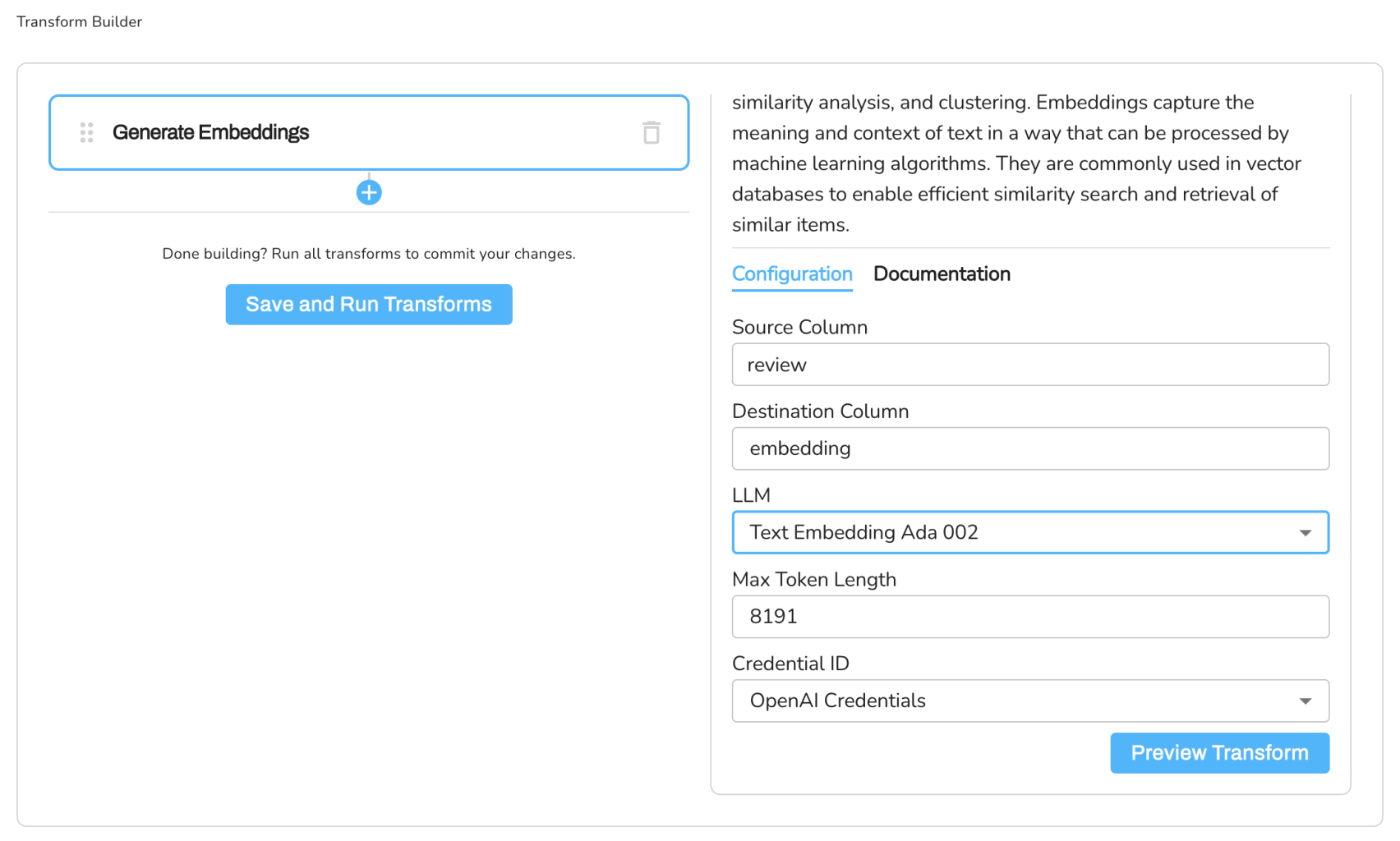
Source Column: review
Destination Column: embedding
Embedding Model: Text Embedding Ada 002
Max Token Length: 8191
Credential ID: OpenAI
Expected Result Dataset:
| Review ID | Review | Embedding |
|---|---|---|
| 1 | Excellent product, really happy with my purchase. | [0.134, 0.256, ..., -0.321] |
| 2 | Good quality but shipping took longer than expected. | [0.097, -0.216, ..., 0.201] |
In this example, a new column called "embedding" is created, containing the embeddings for the text data in the "review" column. The embeddings are generated using the ada-2 model from OpenAI.
Updated about 3 years ago