Architecture
Mantium is an innovative architecture designed to simplify the process of document retrieval for various applications. It streamlines the traditional pipeline of information extraction and retrieval, significantly reducing the number of steps a user has to undertake.
Traditional Workflow
In a typical setting, the user would have to perform the following steps:
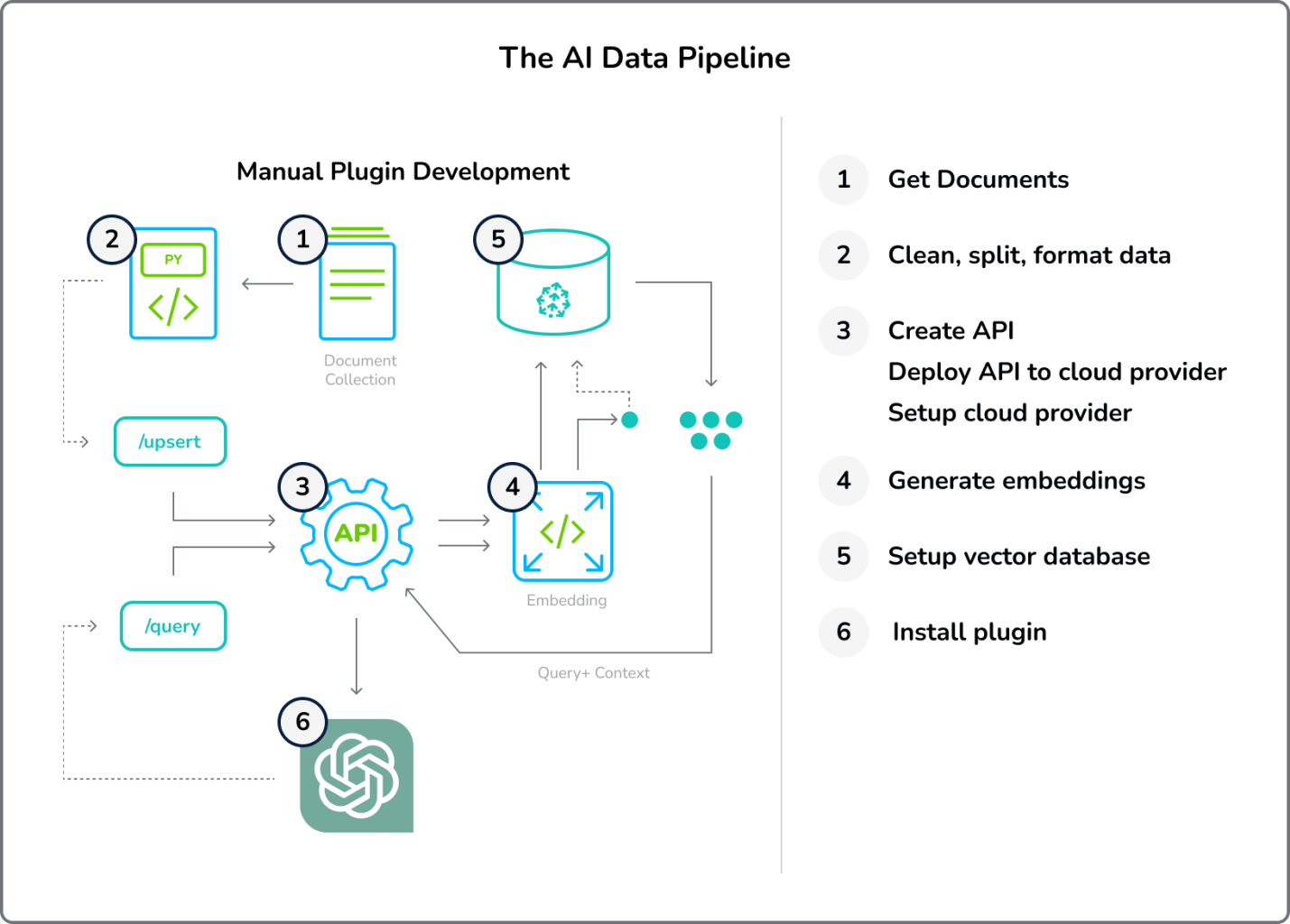
- Gather Documents: The user has to collect all the documents that would be used as the data source.
- Configure Cleaning, Splitting, and Embedding of Documents: The documents need to be preprocessed, which includes cleaning (removing unwanted noise), splitting (breaking down the documents into manageable pieces), and embedding (transforming text data into numeric vectors).
- Code and Deploy a REST Interface: The user needs to write code for the REST API that can handle the interaction between the user and the data source.
- Set Up Cloud Provider: Cloud providers like Digital Ocean are used to host the application and the data.
- Set Up Vector Database: This is a database that stores the vector representation of the documents for faster retrieval.
- Install Plugin: The necessary plugins have to be installed to enable the above functionalities.
The Mantium Way
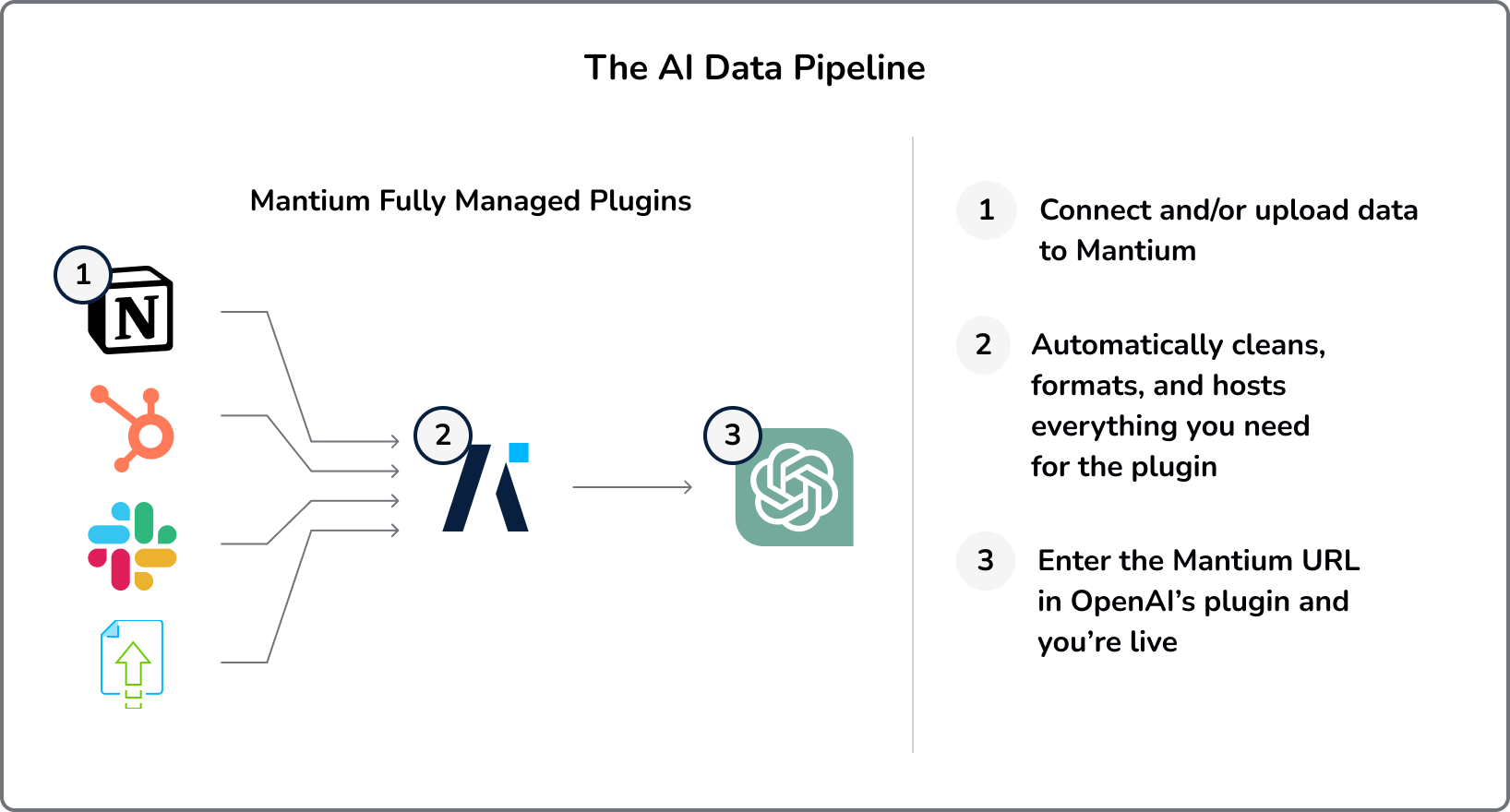
With Mantium, the process is drastically simplified. A user just needs to do the following:
- Upload their Data: Mantium allows users to directly upload their documents into the system. The documents can be in various formats, and Mantium will handle the preprocessing.
- Cleans, Formats, and Hosts Everything: You can either use our pre-set transformations that clean, split, and embed your documents or you can manually configure your data pipeline as you want. Mantium will spin up a rest endpoint for OpenAI to use and connect it to either our fully managed vector database power by Redis or you can connect your own Pinecone vector database.
- Install the Plugin: The only requirement for the user is to install the Mantium plugin. The plugin handles all other configurations and setups, abstracting the complexities away from the user.
By reducing the steps involved and handling the complexity behind the scenes, Mantium provides a more efficient and user-friendly approach to document retrieval.
Updated about 3 years ago
Did this page help you?