How to Summarize Arxiv Papers with Mantium
In this article, we explore how to use Mantium to summarize long ArXiv papers, helping you stay on top of important research and keep yourself informed quickly.
Introduction
In this tutorial, we will demonstrate how users can harness the power of the Mantium PDF Data Connector to unlock insights from ArXiv papers. By using the PDF Data Connector in Mantium, users can import PDFs, transform data, and generate summaries for further analysis.
We will focus on importing PDFs of ArXiv papers, extracting the text, generating summaries, and synchronizing the data.
Objective
Our goal is to use the PDF Data Connector in Mantium's platform, import PDFs from selected ArXiv papers, extract the text, and apply the summarized text data transformation.
Video
We understand that sometimes it's easier to learn by watching rather than reading. If you prefer a more visual explanation, feel free to check out our accompanying video tutorial below. If you prefer reading or are unable to watch the video, please continue with the text documentation.
Prerequisites
Take a few moments to set up the API key for OpenAI.
Import Data from ArXiv Using the PDF Data Connector
- Navigate to the Data Sources section by clicking Data Source on the left navigation bar.
- Click
Add Data Source, and Select the PDF Data Connector from the Data Sources list. - Provide the information to label the Data Source, and click Save and Test.
- On the next page, the sync job will start automatically. If it doesn't, click on “Manual Sync” at the top right corner, to perform the initial sync.
- Wait a few moments for the sync to be completed, and Navigate to
Filesto upload your papers in.pdfformat. - Click on the
Finish and Syncbutton to complete the upload process. - At this point, we have successfully imported PDFs of ArXiv papers using the PDF Data Connector.
Create New Dataset
Datasets serve as the central workspace where you can apply transformations and enrichments to data retrieved from various sources, enabling you to modify and analyze the data without impacting the original information.
To create a new dataset:
- After the sync is completed, Click on the
Create Custom Datasetsbutton in the Data Source section. - Alternatively, you can create datasets by navigating to the Datasets section on the left pane.
- Provide a Dataset name, and select where the data comes from (PDF Data Connector).
- Click on Save to save your configuration, and wait for the job to complete.
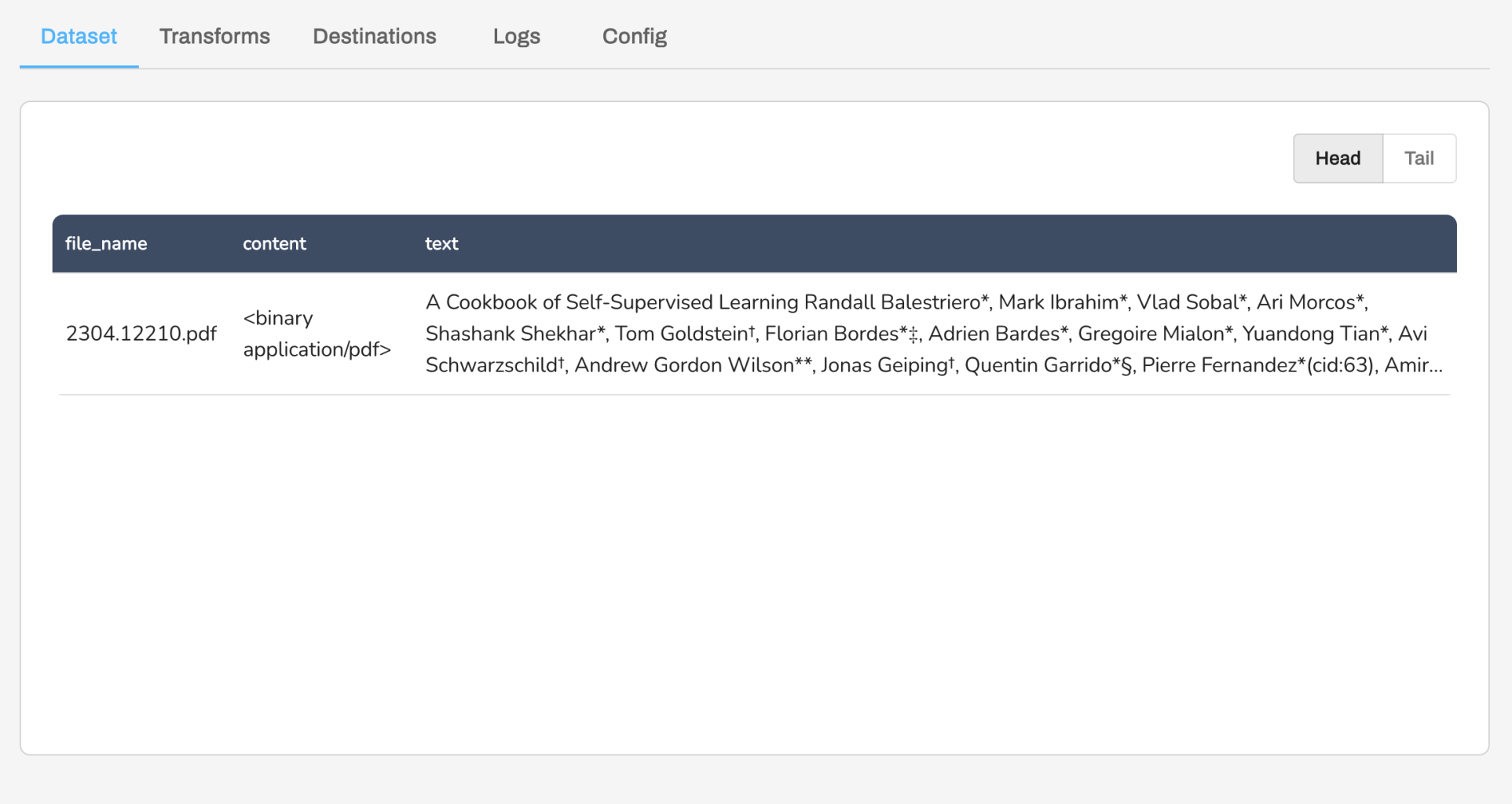
See an example of the Arxiv datasets below
Apply Transformation
After creating datasets from the PDF Data Connector, it’s time to apply transformations that will extract and restructure the texts.
Convert PDF to Text
Notice that we have a text column automatically generated, we can proceed to apply the Summarize Text from, here.
If you don't have the text column after you've imported PDF, you can follow the steps below to convert PDF files to text.
- Navigate to Transforms in the Datasets section, and select Convert PDF to Text from the list of transforms.
- Configure the Source Column parameter by selecting the column that contains the PDF file to be converted.
- Configure the Destination Column parameter by specifying the name of the new column that will be created with the text data.
- Run the transformation by clicking the Save and Run Transforms button. The resulting dataset will have the specified PDF file converted to text and stored in the new column.
Generate Summaries
To generate summaries of the extracted text content, we will use the Summarize Text transform.
To do this:
- Select the Summarize Text transform from the list of
transforms. - Enter the configuration parameter as shown below.
Source Column: text
Destination Column: summarized_text
LLM Model: Gpt-3.5-turbo
Prompt Template: "Summarize this research paper: $field_source_column Summary:"
Credential ID: OpenAI
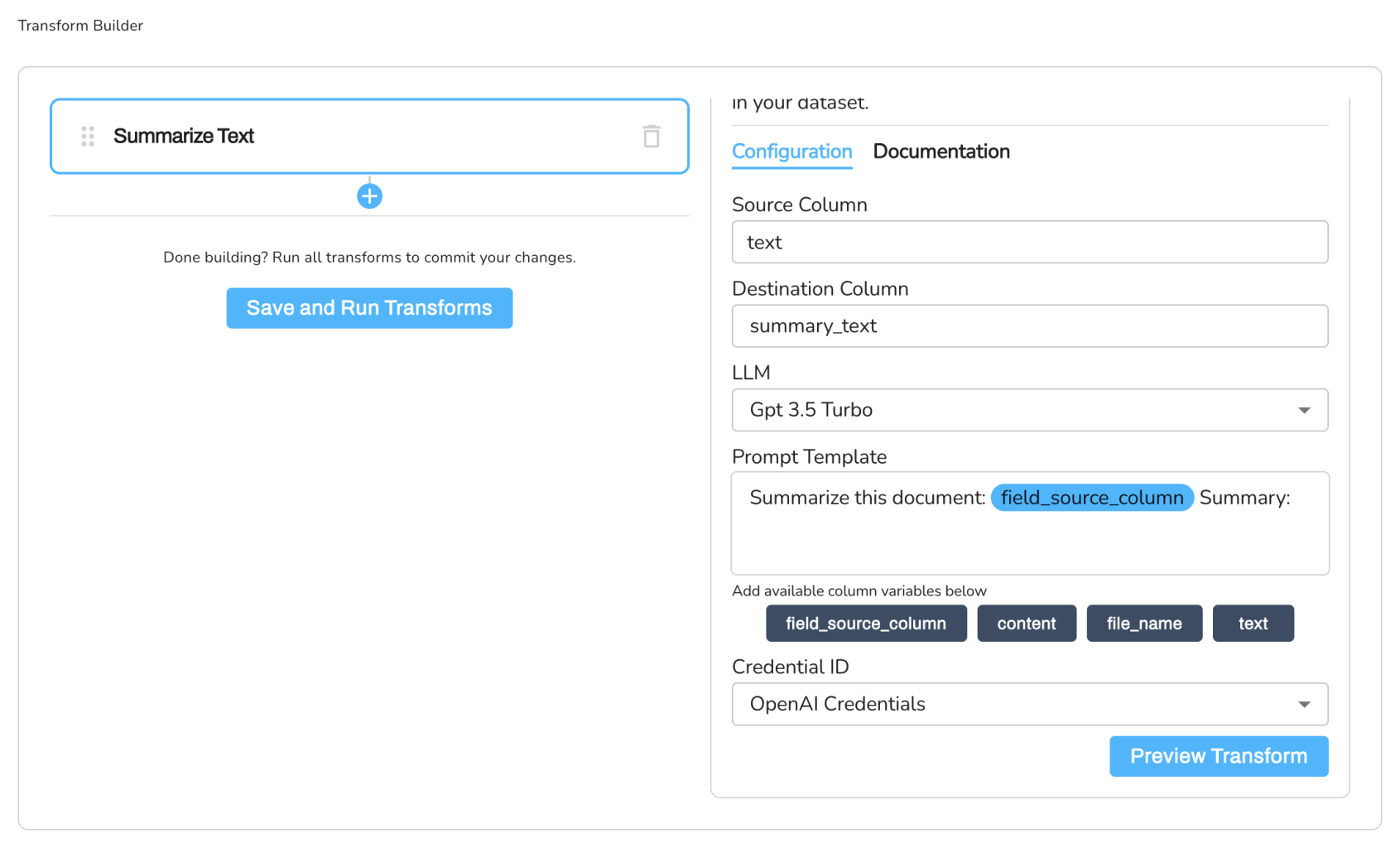
Notice that the Source Column here is the transformed column text from the previous transformation step (Convert PDF to Text). Also, ensure that you have connected your OpenAI credentials to the platform.
- Click on Save and Run Transforms to complete the process.
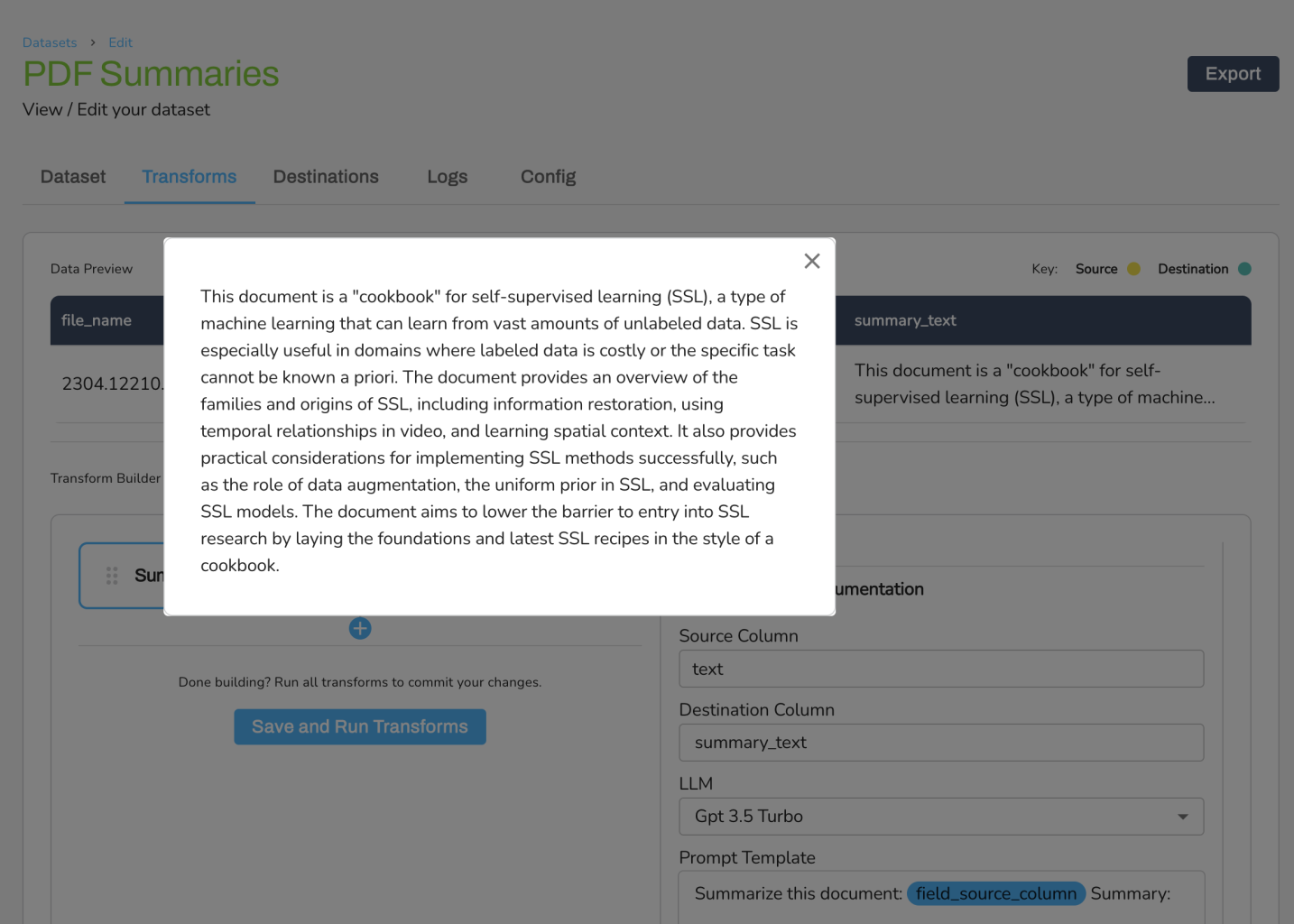
The resulting dataset will contain summarized text for each ArXiv paper, providing you with concise summaries of the research papers. (See image below)
Conclusion
In this tutorial, you learnt how to import data from PDF documents, apply transformations such as Convert PDF to Text and Summarize Text. Here are a few things that you can experiment with next;
- Upload Multiple PDFs in the Data Source section
- Generate embeddings, and ship data to Pinecone. Read this tutorial to learn how.
Updated about 3 years ago